When you use HTTrack to rip websites the software has to translate pages in to html pages with a defined extension of .html
When it creates the pages it adds some custom meta tags in for some reason. According to the HTTrack forums these addtions cannot be turned off which causes messy code.
I want to remove the <!-- Added by HTTrack --> stuff
Index Pages (ie index.html)
<!-- Added by HTTrack --><meta http-equiv="content-type" content="text/html;charset=UTF-8" /><!-- /Added by HTTrack -->
Other Pages (before <head> and after </body>)
<!-- Created by HTTrack Website Copier/3.48-21 [XR&CO'2014] -->
Solutions
Turn off 'HTML footer'
you can remove the 'Created by HTTrack....' comments before the <head> tag and after the </body> tag by doing the following before ripping the site
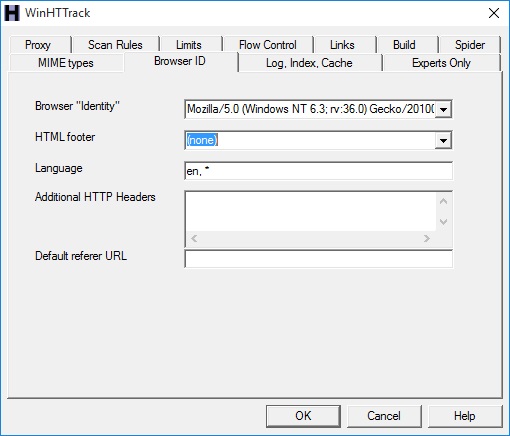
- Goto 'Set Options'
- Select the 'Browser ID' Tab
- Set 'HTML Footer' to (none)
Some Command Line Switches
You can use some command line switches when ripping a website to prevent the comments being added but they are not perfect or complete.
- --preserve : You can you can turn off the page link and charset rewrite using this option but it forces the site to be generated using -K4 option, that preserves the original links. I am not 100% if it removes the <!-- Added by HTTrack -->
- --footer " " : This swith basically swaps the footer tag output (and i guess the <head> tag) with nothing, a workaround more than an option
- the space in --footer" " might be optional for this trick to work
After Rip
To remove the 'content-type...' meta tag and <!-- Added by HTTrack --> added by HTTrack you will have to do one of the following as there is no in-built fix for this. It might be added on purpose to make sure that the web pages load.
- Remove the new tags manually with a text editor
- Write a script with a programming language using regex to find and remove the offending meta tags
- Use a text replace utility such as ecobyte Replace Text